Business Intelligence and Analytics Consultings

Business Intelligence and Analytics: We employ data management solutions established for corporations and enterprises to collect historical and current data while using statistics and software to analyse raw data and give insights for better future decisions with business intelligence and analytics. We enable firms to obtain top talent or outsource their tasks using resources available through various BI technologies. Data Visualization
Data visualization is the process of converting information into a visual representation, such as a map or graph, to make data simpler and extract insights from it. Data visualization's major purpose is to make it easier to spot patterns, trends, and outliers in massive data sets. Information graphics, visual analytics, and statistical graphics are all terms that are frequently used simultaneously.
Data visualisation is one of the processes in the data science process, according to which data must be visualised after it has been collected, analyzed, and modelled to make inferences. Data visualisation is part of the larger data presentation architecture (DPA) discipline, which strives to efficiently identify, find, modify, prepare, and transmit data.
Almost every profession requires data visualisation. Teachers may use it to display student exam results, computer scientists can use it to research artificial intelligence (AI), and CEOs can use it to share information with stakeholders. It is also crucial in large-scale data efforts. Businesses required a way to rapidly and easily acquire an overview of their data as they amassed large amounts of data during the early years of the big data trend. The use of visualisation software was a perfect match.
For similar reasons, sophisticated analytics relies heavily on visualisation. When a data scientist is creating advanced predictive analytics or machine learning (ML) algorithms, it's critical to display the outputs to keep track of outcomes and confirm that the models are working as expected. This is because visual representations of complex algorithms are usually easier to understand than statistical outputs.
Why is data visualization important?Data visualisation is a simple and efficient approach to convey information to a broad audience using visual data. The practice can also assist businesses in determining which factors influence customer behaviour, identifying areas that need to be improved or given more attention, making data more memorable for stakeholders, determining when and where different products should be placed, and forecasting sales volumes.
Other benefits of data visualization include the following:
- an improved ability to maintain the audience's interest with the information they can understand.
- an easy distribution of information that increases the opportunity to share insights with everyone involved
- the ability to absorb information quickly, improve insights, and make faster decisions.
- an increased understanding of the next steps that must be taken to improve the organisation.
- an improved ability to maintain the audience's interest with the information they can understand.s
The act of consuming, storing, organising, and preserving data created and collected by an organisation is known as data management. Effective data management is a critical component of establishing IT systems that run business applications and provide analytical data to help corporate executives, business managers, and other end users make operational and strategic decisions.
The data management process entails several activities that work together to ensure that data in business systems is correct, accessible, and available. The majority of the work is done by IT and data management teams, but business users are usually involved in some phases of the process to ensure that the data fulfils their needs and make sure that they are on board with the policies that govern its use.
This thorough reference to data management delves deeper into what it is and what disciplines it encompasses, as well as best practices for data management, organisational difficulties, and the business benefits of a successful data management plan. There's also a rundown of data management tools and approaches. Read about data management trends and obtain expert guidance on managing corporate data by using the page's hyperlinks.
Importance of data managementData is increasingly being viewed as a corporate asset that can be used to make better business decisions, improve marketing efforts, streamline operations, and cut expenses, all to boost revenue and profits. However, a lack of adequate data management can leave businesses with incompatible data silos, inconsistent data sets, and data quality issues, limiting their capacity to operate business intelligence (BI) and analytics applications � or, worse, leading to erroneous findings.
As businesses are subjected to an increasing number of regulatory compliance requirements, including data privacy and protection regulations such as GDPR and the California Consumer Privacy Act, data management has become increasingly important. Furthermore, businesses are capturing higher amounts of data and a broader range of data kinds, both of which are trademarks of the big data platforms that many have implemented. Such environments can grow bulky and difficult to traverse without proper data management.
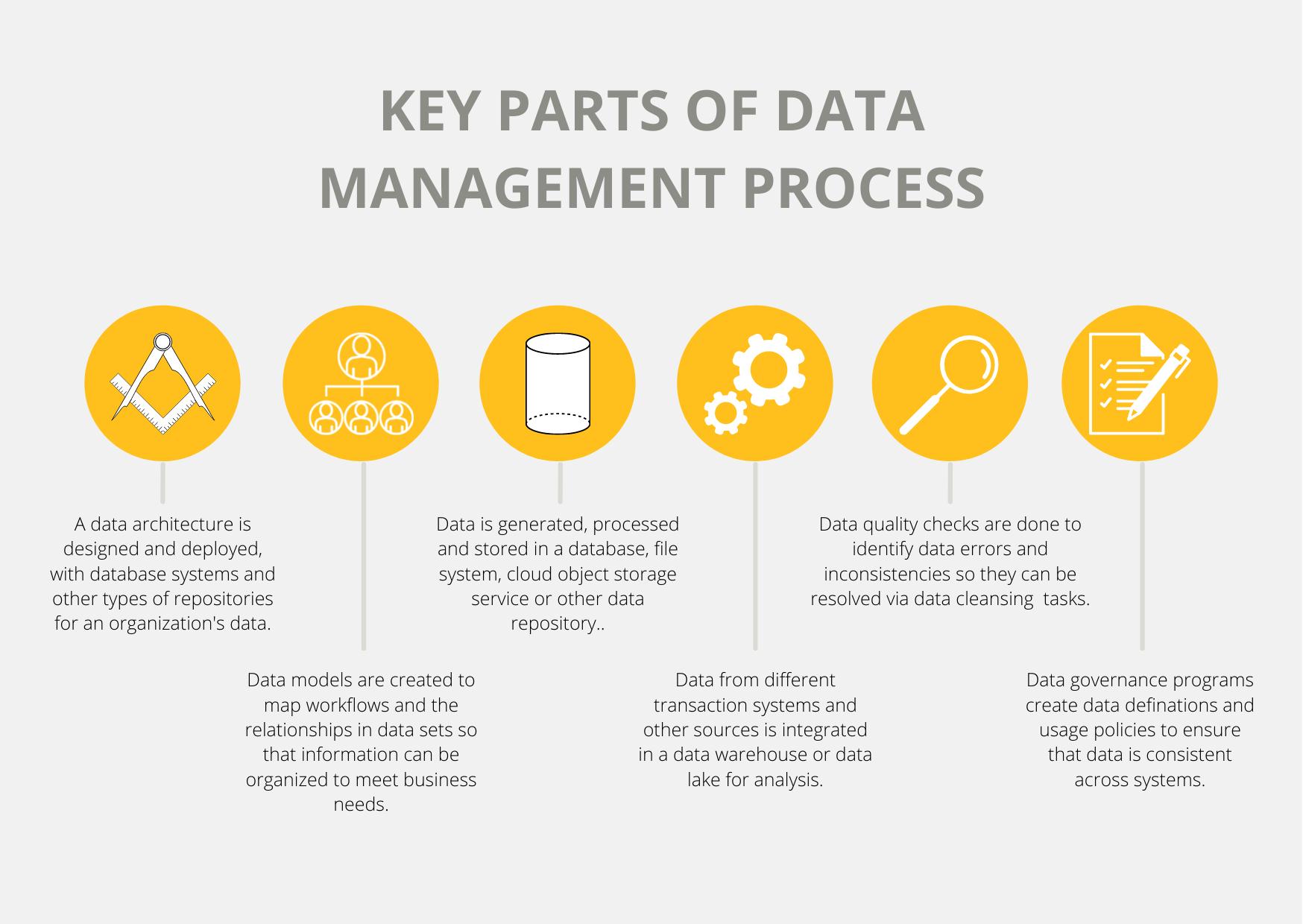
Types of data management functionsThe several disciplines that make up the entire data management process span a range of activities, from data processing and storage to data governance and application in operational and analytical systems. The initial stage, especially in large organisations with a lot of data to handle, is often to create a data architecture. A design for the databases and other data platforms that will be implemented, including specific technologies to meet unique applications, is provided by the architecture
Databases are the most common platform for storing corporate data; they contain an ordered collection of data that can be accessed, updated, and controlled. They're utilised in data warehouses that hold consolidated data sets from business systems for BI and analytics, as well as transaction processing systems that create operational data like customer records and sales orders.
Database administration is an important part of data management. After databases have been set up, performance monitoring and tweaking must be done to ensure that database queries that users execute to retrieve information from the data stored in them have appropriate response times. Database design, setup, installation, and updates; data security; database backup and recovery; and software upgrades and security patches are among the other administrative chores.
Data management involves a variety of interrelated functions.A database management system (DBMS), which is software that functions as an interface between the databases it manages and the database administrators, end-users, and applications that use them, is the most common technology used to deploy and operate databases. File systems and cloud object storage services are examples of alternative data platforms to databases; they store data in less organised ways than traditional databases, allowing for more flexibility in the sorts of data that may be stored and how it's displayed. As a result, they're not well suited to transactional applications.
A database management system (DBMS), which is software that functions as an interface between the databases it manages and the database administrators, end-users, and applications that use them, is the most common technology used to deploy and operate databases. File systems and cloud object storage services are examples of alternative data platforms to databases; they store data in less organised ways than traditional databases, allowing for more flexibility in the sorts of data that may be stored and how it's displayed. As a result, they're not well suited to transactional applications
 Data management tools and techniques
Data management tools and techniques
As part of the data management process, a variety of technologies, tools, and approaches can be used. This covers the following options for various areas of data management.
Systems for managing databases. The relational database management system is the most common type of DBMS. Relational databases arrange data into tables with rows and columns containing database records; related information in separate tables can be linked using primary and foreign keys, eliminating the need for duplicate data entry. Relational databases are based on the SQL programming language and have a strict data format that is best suited for structured transaction data. Because of this, as well as their support for the ACID transaction attributes of atomicity, consistency, isolation, and durability, they are the most popular database for transaction processing.
Other types of DBMS systems, on the other hand, have emerged as viable solutions for certain types of data workloads. Most are classified as NoSQL databases because they don't have strict data models or database schemas. As a result, they can store unstructured and semistructured data such as sensor data, internet clickstream records, and network, server, and application logs. Document databases, which store data elements in document-like structures, key-value databases, which pair unique keys and associated values, wide column stores, which have tables with a large number of columns, and graph databases, which connect related data elements in a graph format, are the four main types of NoSQL systems. While the moniker "NoSQL" is a misnomer, many NoSQL databases now accept SQL and provide some level of ACID compliance.
In-memory databases, which store data in a server's memory rather than on disc to improve I/O efficiency, and columnar databases, which are tailored toward analytics applications, are two further database and DBMS alternatives. There are still hierarchical databases that run on mainframes that predate the introduction of relational and NoSQL systems. Databases can be deployed on-premises or in the cloud; in addition, several database manufacturers offer managed cloud database services, which handle database deployment, configuration, and administration for customers.
Management of large amounts of data. Because of their capacity to store and manage diverse data types, NoSQL databases are frequently utilised in big data deployments. Open-source technologies such as Hadoop, a distributed processing framework with a file system that works across clusters of commodity computers; the HBase database; the Spark processing engine; and the Kafka, Flink, and Storm stream processing platforms are also extensively used in big data scenarios. Big data systems are increasingly being put in the cloud, including object storage services like Amazon Simple Storage Service (S3).
Data lakes and data warehouses are two types of data storage. Data warehouses and data lakes are two other options for storing analytics data. The more traditional way is data warehousing; a data warehouse is typically based on a relational or columnar database and holds structured data gathered from various operational systems and prepared for analysis. BI querying and enterprise reporting are the most common data warehouse use cases, which allow business analysts and executives to evaluate sales, inventory management, and other important performance metrics.
Data from several business systems are combined in an enterprise data warehouse. Individual subsidiaries and business units with management autonomy may construct their data warehouses in huge corporations. Another option is data marts, which are smaller versions of data warehouses that hold sections of an organization's data for specific departments or user groups. Data lakes, on the other hand, are pools of massive data that may be used for predictive modelling, machine learning, and other sophisticated analytics. Data lakes are most typically created on Hadoop clusters, but they can also be deployed on NoSQL databases or cloud object storage. Different platforms can also be merged in a distributed data lake environment. When data is ingested, it may be processed for analysis, although raw data is frequently retained in a data lake. In this instance, data scientists and other analysts usually prepare their own for specific analytical purposes.
Integration of data. Extract, transform, and load (ETL) is the most generally used data integration technique, which pulls data from source systems, turns it into a uniform format, and then loads the combined data into a data warehouse or other target system. Data integration systems, on the other hand, now support a wide range of additional integration approaches. This includes extract, load, and transform (ELT), a variant of ETL in which data is loaded into the destination platform in its original form. For data integration jobs in data lakes and other large data systems, ELT is a popular solution.
Batch integration methods, such as ETL and ELT, run at regular intervals. Change data capture, which applies changes to data in databases to a data warehouse or other repository, and streaming data integration, which merges streams of real-time data in count continuously ways that data management teams can use to accomplish real-time data integration. Another alternative for data integration is data virtualization, which employs an abstraction layer to generate a virtual view of data from various systems for end-users rather than physically loading the data into a data warehouse.
MDM, data governance, and data quality Data governance is essentially an organisational process; software products that can assist in data governance programme management are available, but they are an optional component. While data management experts may be in charge of governance initiatives, they usually involve a data governance council comprised of company leaders who make decisions on common data definitions and corporate standards for data creation, presentation, and use
Data stewardship is another important part of governance activities, which entails managing data sets and ensuring that end-users follow the established data policies. Depending on the size of a business and the breadth of its governance programme, data steward can be a full-time or part-time position. Data stewards can originate from both business operations and IT; in either case, a thorough understanding of the data they manage is usually required.
Data governance is strongly linked to initiatives to enhance data quality; measurements that quantify changes in an organization's data quality are critical to demonstrating the business value of governance programmes. Data profiling, also known as data scrubbing, searches data sets for outlier values that could be errors; data cleansing, also known as data scrubbing, addresses data errors by altering or eliminating poor data; and data validation, which compares data to predefined quality requirements.
Although MDM hasn't been implemented as broadly as the other two data management roles, it is linked to data governance and data quality. That's partly due to MDM programmes' complexity, which means they're only suitable for large companies. MDM establishes a central registration of master data for certain data domains, referred to as a golden record. The master data is maintained in an MDM hub, which feeds it to analytical systems for consistent enterprise reporting and analysis; the hub can also transmit updated master data back to source systems if required.
Data management best practicesIn businesses with distributed data environments that comprise a broad range of systems, a well-designed data governance programme is a vital component of effective data management techniques. It is also necessary to place a major emphasis on data quality. However, in both circumstances, IT and data management teams cannot succeed on their own. Business executives and users have to be involved to make sure their data needs are met and data quality problems aren't perpetuated. The same applies to data modelling projects.
Furthermore, the large number of databases and other data platforms that might be used necessitates caution while developing a data architecture and analysing and selecting technologies. IT and data managers must ensure that the systems they build are appropriate for the task at hand and will provide the data processing capabilities and analytics data that an organization's business operations demand.
DAMA International, the Data Governance Professionals Organization, and other industry organisations aim to develop data management knowledge and provide best-practices advice. DAMA, for example, has released DAMA-DMBOK: Data Management Body of Knowledge, a reference book aimed at defining a consistent view of data management functions and procedures. The DMBOK, as it is commonly known, was initially published in 2009, and a second edition, the DMBOK2, was launched in 2017.